
About
Education
Experiences
News
- We submit some baseline (AuroraCap, MovieChat, MovieChat-Onevision) and some benchmark (VDC, MovieChat-1K) to lmms-eval (LLaVA team), which enables quick evaluation with just a single line of code.
- We release a new version of MovieChat, which use LLaVA-OneVision as the base model instead of the original VideoLLaMA. The new version is available on Github.
- Our paper Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis is released, and the code is available at website.
- Our paper AuroraCap: Efficient, Performant Video Detailed Captioning and a New Benchmark is released, and the code is available at website.
- We finish CVPR 2024 Long-form Video Understanding Challenge @ LOVEU and presented a summary of the competition results offline.
- Finish my research internship at Microsoft Research Asia (MSRA), Beijing.
- We are hosting CVPR 2024 Long-form Video Understanding Challenge @ LOVEU
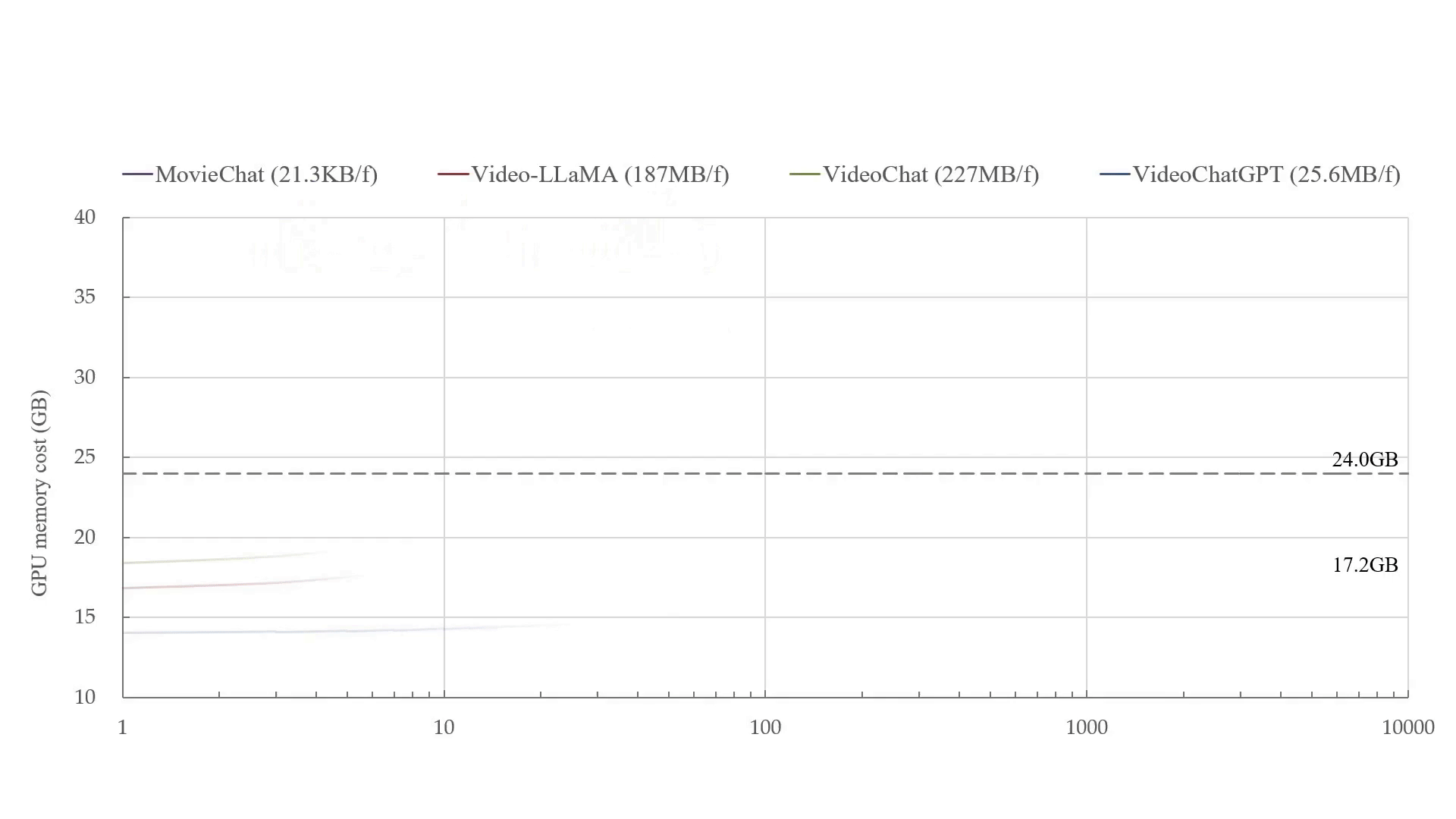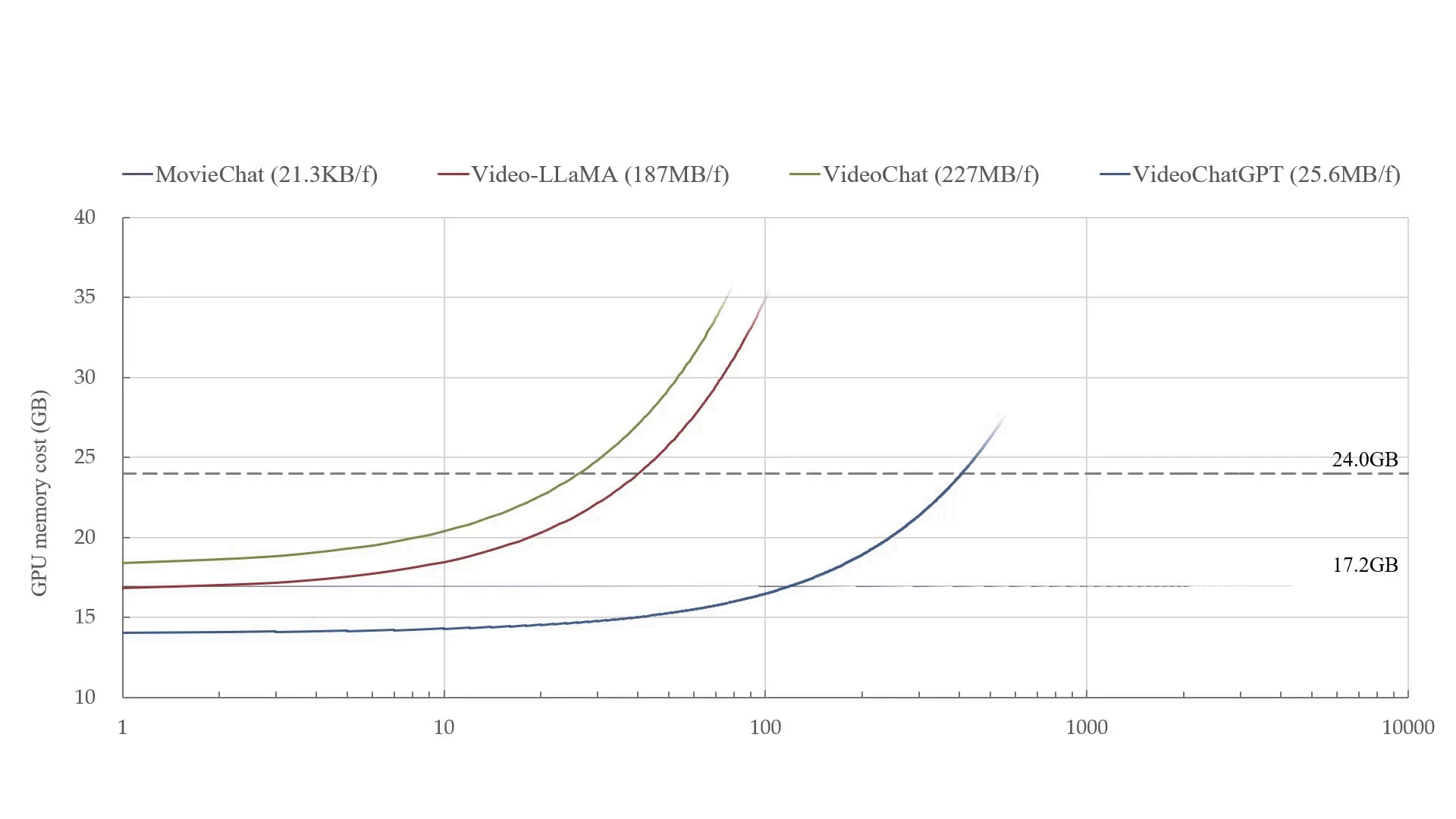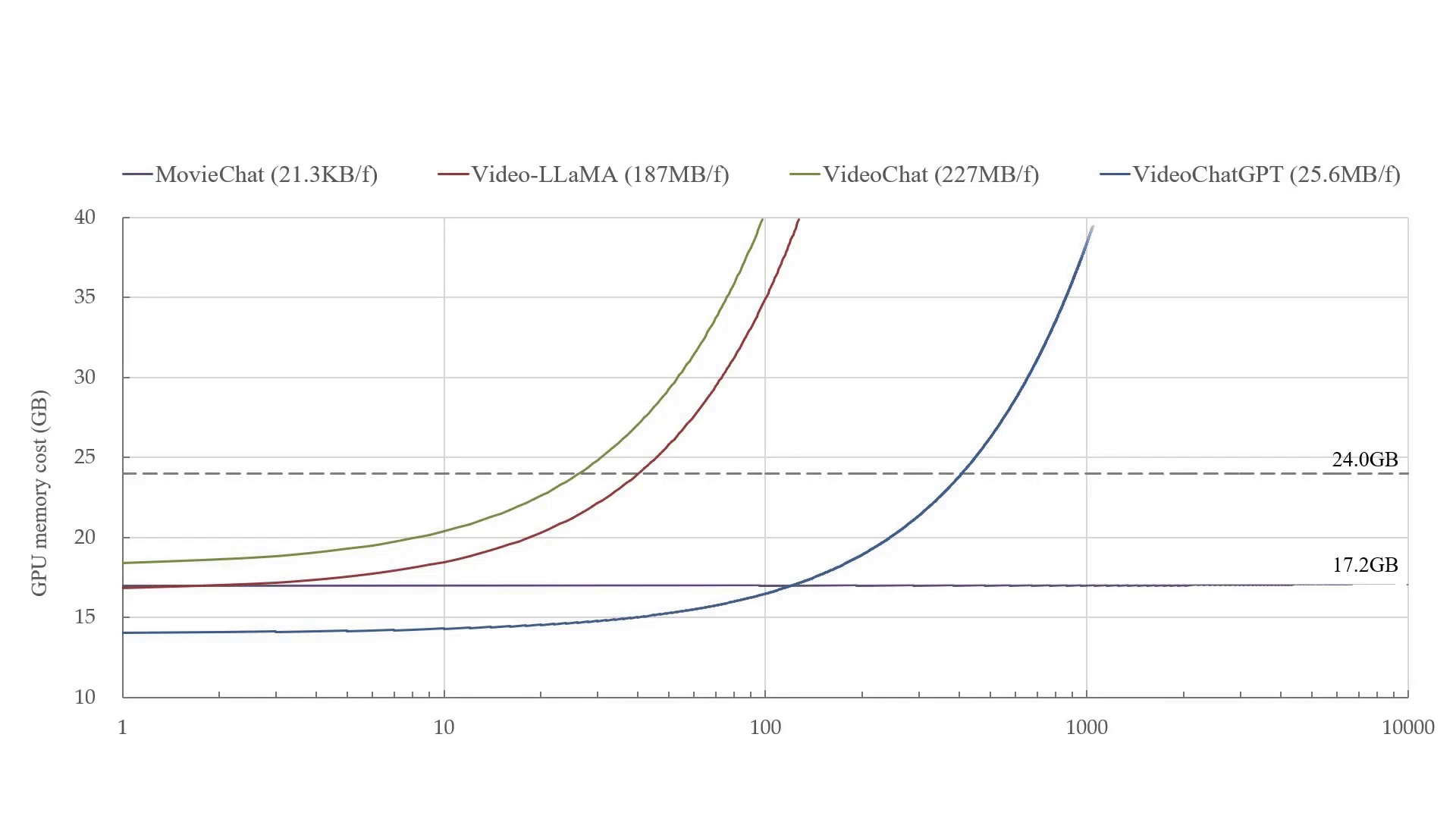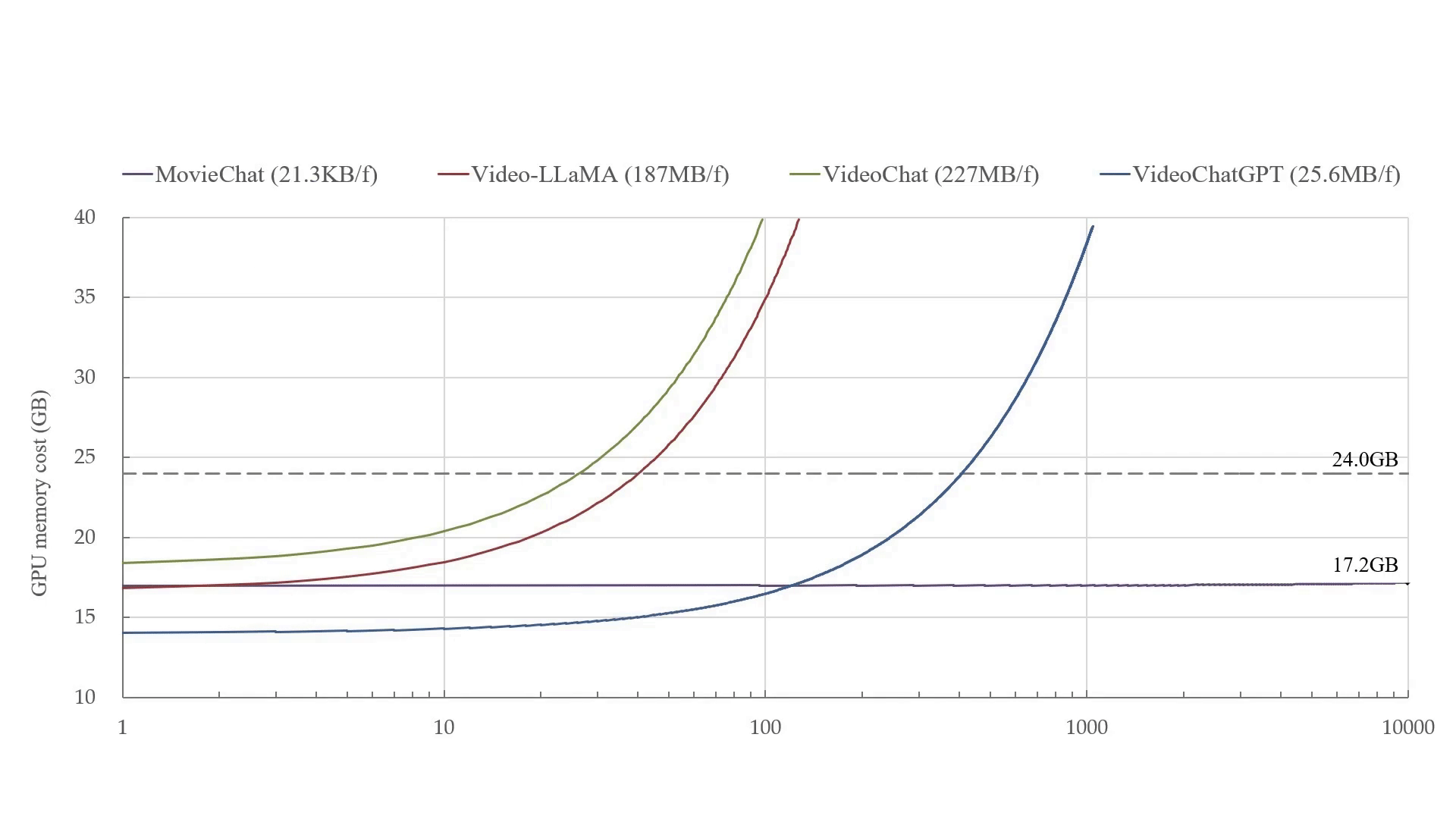
- Our paper MovieChat+: Question-aware Sparse Memory for Long Video Question Answering is released, and the code is available at website.
- Our paper MovieChat: From Dense Token to Sparse Memory in Long Video Understanding is accepted by Computer Vision and Pattern Recognition (CVPR), 2024.
Selected Publications and Manuscripts
* Equal contribution. † Project lead. ‡ Corresponding author.
Also see Google Scholar.



Fantasy: Transformer Meets Transformer in Text-to-Image Generation
Preperint, 2024
Fantasy, an efficient text-to-image generation model marrying the decoder-only Large Language Models (LLMs) and transformer-based masked image modeling (MIM).

Teaching Assistant
Teaching Assistant (TA), with Prof. Gaoang Wang
Selected Honors & Awards
- National Scholarship, 2024 (Zhejiang University)
- National Scholarship, 2021 (Dalian University of Technology)
Top